Use AWS Egress PrivateLink Endpoints for Dedicated Clusters on Confluent Cloud¶
AWS PrivateLink is a networking service that allows one-way connectivity from one VPC to a service provider and is popular for its unique combination of security and simplicity.
Confluent Cloud, available through AWS Marketplace or directly from Confluent, supports outbound AWS PrivateLink connections using Egress PrivateLink Endpoints. Egress PrivateLink Endpoints are AWS interface VPC Endpoints, and they enable Confluent Cloud clusters to access supported AWS services and other endpoint services powered by AWS PrivateLink, such as AWS S3, a SaaS service, or a PrivateLink Service that you create yourself.
The following diagram summarizes the Egress PrivateLink Endpoint architecture between Confluent Cloud and various potential destinations.
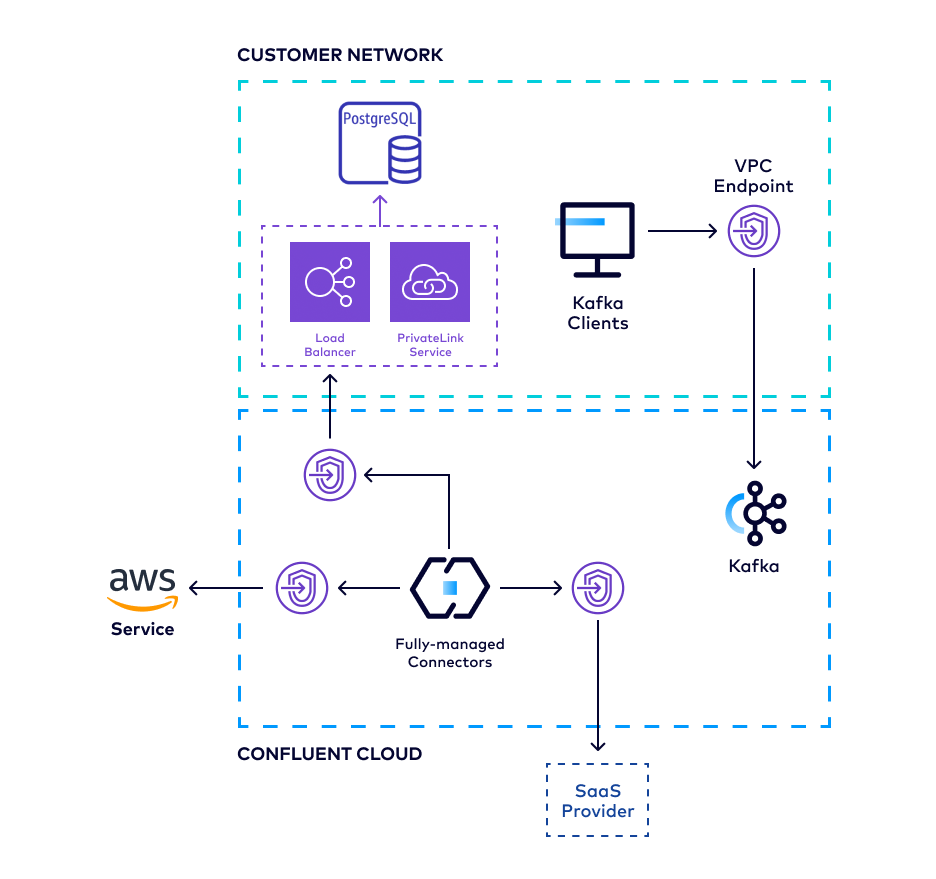
The high-level workflow to set up an Egress PrivateLink Endpoint from Confluent Cloud to an external system, such as for managed connectors:
Identify a Confluent Cloud network you want to use, or set up a new Confluent Cloud network.
Obtain the AWS PrivateLink Service name.
For certain target systems, you can retrieve the service name as part of the guided workflow while creating an Egress PrivateLink Endpoint in the next step.
[Optional] Create private DNS records for use with AWS VPC endpoints.
For service/connector-specific setup, see the target system networking supportability table.
Requirements and considerations¶
Review the following requirements and considerations before you set up an Egress PrivateLink Endpoint using AWS PrivateLink:
Egress PrivateLink Endpoints described in this document is only available for use with Dedicated clusters inside a “PrivateLink Access” type network.
For use with Enterprise clusters, see Use AWS Egress PrivateLink Endpoints for Serverless Products on Confluent Cloud.
The AWS PrivateLink service must be configured to allow access from Confluent Cloud’s account or IAM role.
Due to differing granularity of the allowlist configuration across SaaS providers, it is recommended that you leverage provider-specific controls (like network rules) for securing access to the PrivateLink services against confused deputy type issues.
Egress PrivateLink Endpoints can only be used by fully managed connectors.
AWS does not support cross-region connections with PrivateLink.
When using Egress PrivateLink Endpoints, additional charges may apply, for example, for certain connector configurations. For more information, see the following pricing information:
Obtain AWS PrivateLink Service name¶
To make an AWS PrivateLink connection from Confluent Cloud to an external system, you must first obtain an AWS PrivateLink Service name for Confluent to establish a connection to.
Depending on the system you wish to connect to, there may be different allowlist requirements to allow Confluent access. It is recommended that you check each system’s allowlist mechanism to verify that Confluent Cloud will be able to create an endpoint targeting that system.
For AWS services¶
Refer to the AWS documentation for a list of all AWS services that integrate with AWS PrivateLink and their associated service names.
For 3rd party services¶
Refer to the system provider’s documentation for how to obtain the AWS PrivateLink Service name and to determine allowlisting requirements.
The following are reference links for some of the popular system providers: :
For AWS PrivateLink Services you create¶
Refer to the AWS documentation for how to make your endpoint service available to service consumers.
For step-by-step guide on how to set up an Egress PrivateLink to connect to self-managed services, see the Confluent Cloud connector document.
Manage access to your service¶
When you stand up your own PrivateLink Service, you may want to manage its permissions to restrict who can create endpoints to that service.
Confluent Cloud uses a unique IAM Role to create VPC endpoints for each environment you create an Egress PrivateLink Endpoint from. We highly recommend only allowlisting this principal for maintaining an optimal security posture.
To obtain the IAM Role’s ARN:
- In the Confluent Cloud Console, in the Network Management tab, click the Confluent Cloud network.
- Copy the IAM Principal in the Egress Connections tab.
Create an Egress PrivateLink Endpoint in Confluent Cloud¶
Confluent Cloud Egress PrivateLink Endpoints are AWS interface VPC Endpoints used to connect to AWS PrivateLink Services.
In the Network Management tab of the desired Confluent Cloud environment, click the Confluent Cloud network to which you want to add the PrivateLink Endpoint. The Connection Type of the network you select must be “PrivateLink Access”.
Click Create endpoint in the Egress connections tab.
Click the service you want to connect to.
Follow the guided steps to specify the field values, including:
Name: Name of the PrivateLink Endpoint.
PrivateLink service name: The name of the PrivateLink service you retrieved as part of this guided workflow or as described in Obtain AWS PrivateLink Service name.
Create an endpoint with high availability: Check the box if you wish to deploy an endpoint with High Availability.
Endpoints deployed with high availability have network interfaces deployed in multiple availability zones.
Click Create to create the PrivateLink Endpoint.
If there are additional steps for the specific target service, follow the prompt to complete the tasks, and then click Finish.
Send a request to create an endpoint:
HTTP POST request
POST https://api.confluent.cloud/networking/v1/access-points
Authentication
See Authentication.
Request specification
{
"spec": {
"display_name": "<The custom name for the endpoint>",
"config": {
"kind": "AwsEgressPrivateLinkEndpoint",
"vpc_endpoint_service_name": "<The name of the PrivateLine service you wish to connect to>",
"enable_high_availability": <Provision with high availability>,
},
"environment": {
"id": "<The environment ID where the endpoint belongs to>",
"environment": "<Environment of the referred resource, if env-scoped>"
},
"gateway": {
"id": "<The gateway ID to which this belongs>",
"environment": "<Environment of the referred resource, if env-scoped>"
}
}
}
vpc_endpoint_service_name: See Obtain AWS PrivateLink Service name.enable_high_availability: Set totrueto deploy an endpoint with high availability. The default isfalse.Endpoints deployed with high availability have network interfaces deployed in multiple availability zones.
gateway.id: Issue the following API request to get the gateway id.GET https://api.confluent.cloud/networking/v1/networks/{Confluent Cloud network ID}You can find the gateway id in the response under
spec.gateway.id.
An example request spec to create an endpoint:
{
"spec": {
"display_name": "prod-plap-egress-usw2",
"config": {
"kind": "AwsPrivateLinkEndpoint",
"vpc_endpoint_service_name": "com.amazonaws.vpce.us-west-2.vpce-svc-00000000000000000",
"enable_high_availability": false,
},
"environment": {
"id": "env-00000",
},
"gateway": {
"id": "gw-00000",
}
}
}
Use the confluent network access-point private-link egress-endpoint create Confluent CLI command to create an Egress PrivateLink Endpoint:
confluent network access-point private-link egress-endpoint create [name] [flags]
The following are the command-specific flags:
--cloud: Required. The cloud provider. Set toaws.--service: Required. Name of an AWS VPC endpoint service that you retrieved in Obtain AWS PrivateLink Service name.--gateway: Required. Gateway ID.--high-availability: enable high availability for AWS egress endpoint. Endpoints deployed with high availability have network interfaces deployed in multiple availability zones.
You can specify additional optional CLI flags described in the Confluent
CLI command reference,
such as --environment.
The following is an example Confluent CLI command to create an AWS Egress PrivateLink Endpoint with high availability:
confluent network access-point private-link egress-endpoint create \
--cloud aws \
--gateway gw-123456 \
--service com.amazonaws.vpce.us-west-2.vpce-svc-00000000000000000 \
--high-availability
You can specify additional optional CLI flags described in the Confluent
CLI command reference,
such as --environment.
Use the confluent_access_point resource to create an Egress PrivateLink Endpoint.
An example snippet of Terraform configuration:
resource "confluent_environment" "development" {
display_name = "Development"
}
resource "confluent_access_point" "main" {
display_name = "access_point"
environment {
id = confluent_environment.development.id
}
gateway {
id = confluent_network.main.gateway[0].id
}
aws_egress_private_link_endpoint {
vpc_endpoint_service_name = "com.amazonaws.vpce.us-west-2.vpce-svc-00000000000000000"
}
}
Your Egress PrivateLink Endpoint status will transition from “Provisioning” to “Ready” in the Confluent Cloud Console when the endpoint has been created and can be used.
Once the endpoint is created, connectors provisioned against Kafka clusters in the same network can leverage the Egress PrivateLink Endpoint to access the external data.
Confluent Cloud exposes the VPC Endpoint ID for each of the above Egress PrivateLink Endpoints so that you can use it in various network-related policies, such as in an S3 bucket policy or Snowflake Network rule.
Create a private DNS record in Confluent Cloud¶
Create private DNS records for use with AWS VPC endpoints.
Not all service providers set up public DNS records to be used when connecting to them with AWS PrivateLink. For situations where a system provider requires setting up private DNS records in conjunction with AWS PrivateLink, you need to create DNS records in Confluent Cloud.
Before you create a DNS Record, you need to first create an Egress PrivateLink Endpoint and use the Egress PrivateLink Endpoint ID for the DNS record.
AWS private DNS names are not supported.
When creating DNS records, Confluent Cloud creates a single * record that maps
the domain name you specify to the DNS name of the VPC endpoint.
For example, in setting up DNS records for Snowflake, the DNS zone configuration will look like:
*.xy12345.us-west-2.privatelink.snowflakecomputing.com CNAME vpce-0cb12cd2dc02130cf-8s6uwimu.vpce-svc-03bc1ff023623a033.us-east-1.vpce.amazonaws.com TTL 60
- In the Network Management tab of your environment, click the Confluent Cloud network you want to add the DNS record to.
- In the Egress DNS tab, click Create DNS record.
- Specify the following field values:
- Egress PrivateLink Endpoint: The Egress PrivateLink Endpoint ID you created in create an Egress PrivateLink Endpoint
- Domain: The domain of the private link service you wish to access. Get the domain value from the private link service provider, AWS or a third-party provider.
- Click Save.
Send a request to create a DNS Record that is associated with a PrivateLink Endpoint that is associated with a gateway.
HTTP POST request
POST https://api.confluent.cloud/networking/v1/dns-records
Authentication
See Authentication.
Request specification
{
"spec": {
"display_name": "The name of this DNS record",
"domain": "<The fully qualified domain name of the external system>",
"config": {
"kind": "PrivateLinkAccessPoint",
"resource_id": "<The ID of the endpoint that you created>"
},
"environment": {
"id": "<The environment ID where this resource belongs to>",
"environment": "<Environment of the referred resource, if env-scoped>"
},
"gateway": {
"id": "<The gateway ID to which this belongs>",
"environment": "<Environment of the referred resource, if env-scoped>"
}
}
}
domain: Get the value from the private link service provider, AWS, or a third-party provider.gateway.id: Issue the following API request to get the gateway ID.GET https://api.confluent.cloud/networking/v1/networks/{Confluent Cloud network ID}You can find the gateway ID in the response under
spec.gateway.id.
An example request spec to create a DNS record:
{
"spec": {
"display_name": "prod-dns-record1",
"domain": "example.com",
"config": {
"kind": "PrivateLinkAccessPoint",
"resource_id": "plap-12345"
},
"environment": {
"id": "env-00000",
},
"gateway": {
"id": "gw-00000",
}
}
}
Use the confluent network dns record create Confluent CLI command to create a DNS record:
confluent network dns record create [name] [flags]
The following are the command-specific flags:
--private-link-access-point: Required. Private Link Endpoint ID.--gateway: Required. Gateway ID.--domain: Required. Fully qualified domain name of the external system. Get the domain value from the private link service provider, AWS or a third-party provider.
You can specify additional optional CLI flags described in the Confluent
CLI command reference,
such as --environment.
The following is an example Confluent CLI command to create DNS record for an endpoint:
confluent network dns record create my-dns-record \
--gateway gw-123456 \
--private-link-access-point ap-123456 \
--domain xy12345.us-west-2.privatelink.snowflakecomputing.com
Use the confluent_dns_record resource to create DNS records.
An example snippet of Terraform configuration:
resource "confluent_environment" "development" {
display_name = "Development"
}
resource "confluent_dns_record" "main" {
display_name = "dns_record"
environment {
id = confluent_environment.development.id
}
domain = "example.com"
gateway {
id = confluent_network.main.gateway[0].id
}
private_link_access_point {
id = confluent_access_point.main.id
}
}
Support for AWS PrivateLink Service configuration¶
Confluent Support can help with issues you may encounter when creating an Egress PrivateLink Endpoint to a specific service.
For any service-side problems, such as described below, Confluent is not responsible for proper AWS PrivateLink Service configuration or setup:
- If you need help setting up an AWS PrivateLink Service for data systems running within your environment or VPC that you want to connect to from Confluent Cloud, contact AWS for configuration help and best practices.
- If you need help configuring AWS PrivateLink Services for those managed by a third-party provider or service, contact that provider for compatibility and proper setup.
Next steps¶
Try Confluent Cloud on AWS Marketplace with $1000 of free usage for 30 days, and pay as you go. No credit card is required.